
Sensori i presionit 3408560 për pjesët e motorit me naftë Cummins QSK


Detaje
Lloji i marketingut:Produkt i nxehtë 2019
Vendi i origjinës:Zhejiang, Kinë
Emri i markës:Bark
Garancia:1 vit
Pjesa Nr:3408560
Lloji:sensor presioni
Cilësia:Me cilësi të lartë
Shërbimi pas shitjes ofroi:Mbështetje në internet
Paketimi:Paketim neutral
Koha e dorëzimit:5-15 ditë
Parathënie e Produkteve
Sipas metodave të ndryshme të përpunimit të të dhënave, ekzistojnë tre arkitektura të sistemit të shkrirjes së informacionit: shpërndarë, të centralizuar dhe hibrid.
1) Shpërndarë: Së pari, të dhënat origjinale të marra nga sensorë të pavarur përpunohen në vend, dhe më pas rezultatet dërgohen në Qendrën e Fuzionit të Informacionit për optimizim inteligjent dhe kombinim për të marrë rezultatet përfundimtare. Shpërndarja ka kërkesë të ulët për bandwidth të komunikimit, shpejtësinë e shpejtë të llogaritjes, besueshmërinë e mirë dhe vazhdimësinë, por saktësia e gjurmimit është shumë më pak se ajo e një të centralizuar. Struktura e shkrirjes e shpërndarë mund të ndahet në strukturën e shpërndarë të shkrirjes me reagime dhe strukturë të shpërndarë të shkrirjes pa reagime.
2) Centralizimi: Centralizimi dërgon të dhënat e papërpunuara të marra nga secili sensor direkt në procesorin qendror për përpunimin e bashkimit, i cili mund të realizojë bashkimin në kohë reale. Saktësia e saj për përpunimin e të dhënave është e lartë dhe algoritmi i tij është fleksibël, por disavantazhet e tij janë kërkesa të larta për procesorin, besueshmërinë e ulët dhe vëllimin e madh të të dhënave, kështu që është e vështirë të realizohet;
3) Hybrid: Në kornizën e shkrirjes së informacionit shumë-sensor hibrid, disa sensorë miratojnë modalitetin e centralizuar të shkrirjes, dhe pjesa tjetër miraton modalitetin e shpërndarë të shkrirjes. Kuadri hibrid i bashkimit ka përshtatshmëri të fortë, merr parasysh avantazhet e bashkimit dhe shpërndarjes së centralizuar dhe ka një stabilitet të fortë. Struktura e mënyrës së shkrirjes hibride është më e komplikuar se ajo e dy mënyrave të para të shkrirjes, gjë që rrit koston e komunikimit dhe llogaritjes.
Kalman Filter (KF)
Procesi i përpunimit të informacionit nga Kalman Filter është përgjithësisht parashikim dhe korrigjim. Nuk është vetëm një algoritëm i thjeshtë dhe i betonit, por edhe një skemë shumë e dobishme e përpunimit të sistemit në rolin e teknologjisë së bashkimit të informacionit me shumë sensorë. Në fakt, është e ngjashme me metodat e shumë sistemeve të përpunimit të të dhënave të informacionit. Ajo siguron një vlerësim efektiv statistikor optimal për të dhënat e shkrirë me anë të llogaritjes matematikore përsëritëse rekursive, por kërkon pak hapësirë dhe llogaritje të ruajtjes, kështu që është i përshtatshëm për mjedisin me hapësirë dhe shpejtësi të kufizuar të përpunimit të të dhënave. KF mund të ndahet në dy lloje: Filter Kalman i shpërndarë (DKF) dhe Filter i zgjatur Kalman (EKF). DKF mund të bëjë që shkrirja e të dhënave të decentralizohet plotësisht, ndërsa EKF mund të kapërcejë në mënyrë efektive ndikimin e gabimeve të përpunimit të të dhënave dhe paqëndrueshmërisë në procesin e bashkimit të informacionit.
Foto e produktit

Detajet e kompanisë







Avantazh i kompanisë
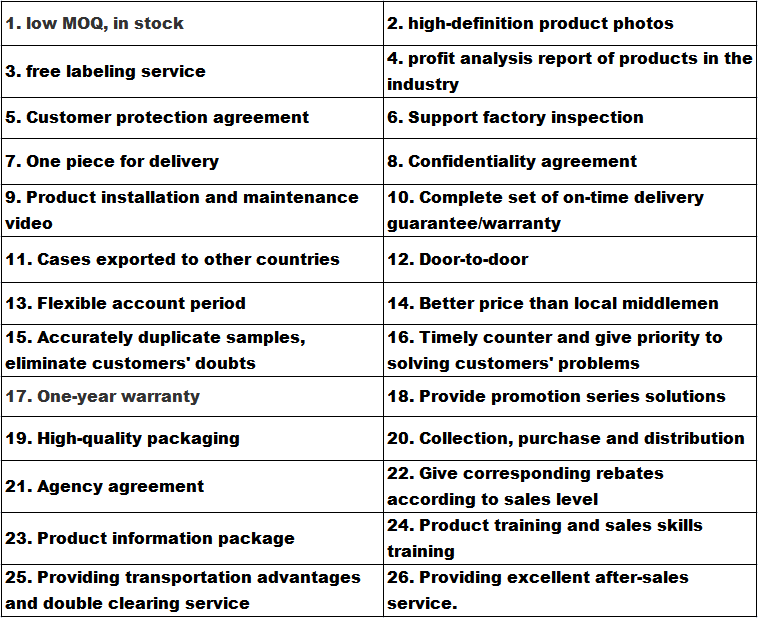
Transportim

Fshat

Produkte të lidhura








